


Julia Hischberg, Tom Mitchell and Alex "Sandy" Pentland deliver their invited plenary talks and Interspeech 2011, Florence, Italy 27-31 August 2011.
Welcome to the Autumn 2011 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. This issue includes 9 articles from 6 guest contributors, and our own staff reporters and editors.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Jason Williams, Editor-in-chief
Pino Di Fabbrizio, Editor
Martin Russell, Editor
Chuck Wooters, Editor
Updates on ICASSP 2012, forthcoming article "Trends in Speech and Language Processing", and speaker and language recognition.
The IEEE Signal Processing Society, our parent organization, also produces a monthly newsletter, "Inside Signal Processing".
Exactly 20 years after the second EUROSPEECH Conference, which was held in Genoa, INTERSPEECH returned to Italy this year, specifically in the cradle of the renaissance, Florence, on 27-31 August 2011.
The Japanese Parliament is now using ASR from Kyoto University and NTT for transcription of all plenary sessions and committee meetings.
Researchers at Columbia are investigating ways to automatically detect intoxication in speech. William Yang Wang, currently a PhD student at Carnegie Mellon that worked on this team while a Master's student, discussed the project and its goals with us.
The latest in the SemDial series of workshops in the semantics and pragmatics of dialogue was recently held in Los Angeles on September 21-23.
Interspeech 2011 was held in Florence, Italy, on 27-31 August. The first three days of the conference began with excellent invited plenary talks by Julia Hirschberg, Tom Mitchell and Alex Pentland.
Over the past few years, IBM Research has been actively involved a project known as Translingual Automatic Language Exploitation System (TALES). The objective of the TALES project is to translate news broadcasts and websites from foreign languages into English. TALES is built on top of the IBM Unstructured Information Management Architecture (UIMA) platform. In this article, we provide an overview of the TALES project and highlight in more detail some of the new research directions.
AVIOS, the Applied Voice Input/Output Society, is a non-profit foundation dedicated to informing and educating developers of speech applications on best practices for application construction and deployment. In early 2006 we decided to focus this goal on students by giving them an opportunity to demonstrate their developmental competence to the speech community. The competition has now grown into an annual contest whose winners are substantially remunerated for their efforts, and whose winning applications are posted on our website.
IVA 2011 is a research conference on Intelligent Virtual Agents. Intelligent Virtual Agents (IVAs) are animated embodied characters with interactive human-like capabilities such as speech, gestures, facial expressions, head and eye movement. Virtual agents have capabilities both to perceive and to exhibit human-like behaviours. Virtual characters enhance user interaction with a dialogue system by adding a visual modality and creating a persona for a dialogue system. They are used in interactive systems as tutors, museum guides, advisers, signers of sign language, and virtual improvisational artists.
This article discusses how cloudcomputing and crowdsourcing are changing the speech science world in both, academia and industry. How are these paradigms interrelated? How do different areas of speech processing make use of cloudcomputing and crowdsourcing? Which role do performance, pricing, security, ethics play?
SLTC Newsletter, October 2011
Interspeech 2011 was held in Florence, Itally, on 27-31 August. The first three days of the conference began with excellent invited plenary talks by Julia Hirschberg, Tom Mitchell and Alex Pentland. As is the norm for these talks, there is not necessarily a printed version in the proceedings. This article presents a summary of those talks and links to relevant publications by the presenters.
My only previous visit to Florence was in 1975. I was a first year undergraduate student on an 'Inter-rail' tour of Europe. I had never been outside the UK, and Florence was the most exotic place that I had ever visited. I looked forward to my return visit for Interspeech 2011 with keen anticipation. I was not disappointed with the conference or the city. In particular the invited plenary talks at the start of each day were fascinating. Each of these talks addressed a different aspect of the interface between speech and language technology and cognitive science. The first, by Julia Hirschberg from Columbia University, examined the phenomenon of entrainment, whereby the communicative styles of individuals engaged in conversation tend to converge, the next talk, by Tom Mitchell from Carnegie Mellon University, described research into the neural representation of words, while the final talk, by Alex Pentland from the MIT Media Laboratory, concerned "honest signals", the subtle patterns of gesture, expression and speech that underpin our interactions with others. This short article presents a summary of the plenary sessions, with links and references to some relevant support information.
Julia Hischberg, Tom Mitchell and Alex "Sandy" Pentland deliver their invited plenary talks and Interspeech 2011, Florence, Italy 27-31 August 2011.
'Entrainment', or adaptation, accommodation, alignment, priming or the 'chameleon effect', refers to the way that, in natural conversational speech, people tend to adapt their communicative behavior to that of their conversational partner. From the perspective of speech technology, this presents both problems and opportunities. For example, in speaker verification entrainment might cause the speech of two individuals to become more difficult to distinguish as their conversation progresses, whereas in a spoken dialogue system the same phenomenon might be exploited to modify different dimensions of a user's speech to improve performance, or to adapt the automatic system to make it more acceptable to the user. Julia presented evidence from published studies of entrainment in many different aspects of spoken language. She then went on to describe her own work and that of her collaborators at Columbia University, investigating evidence of different types of entrainment using the 'Columbia Games Corpus'. She described lexical entrainment, the tendency of individuals to collaborate on their choice of what to call something, how participants in the game converge in terms of their usage of high frequency words and affirmative cue words (different ways of saying "yes"), and how this convergence correlates with task success and dialogue coordination. She then turned from entrainment over entire conversations to evidence of 'local' entrainment in the neighborhood of 'backchannels' - the short utterances that we use to indicate that we are paying attention.
This was a fascinating talk, exposing an aspect of human communication that we are only just beginning to contemplate from the perspective of technology. There are also interesting connections with Alex Pentland's plenary talk, which is described below.
I was astonished by the progress that has been made in this area. Tom described the work conducted by his neurosemantics research team at Carnegie Mellon University on the relationship between word stimuli (in the form of words or images) and the resulting patterns of brain activation in an individual, measured by functional MRI (fMRI). He showed that standard pattern classification techniques can be trained to identify the word corresponding to one of these stimuli from the fMRI pattern. Moreover, he showed that these patterns are sufficiently similar across people that a classifier trained on images from one population can classify the fMRI images of a new subject (including, from the evidence of a video that we were shown, those of a well-known US TV presenter!).
In the next part of his talk Tom described how machine learning techniques can be used to predict patterns of brain activity associated with the meaning of words, transforming machine learning into a tool for studying the brain. This is achieved by representing a word as a vector of latent 'semantic features' and then learning the relationships between these sets of features and the corresponding patterns of brain activity. Thus it becomes possible to predict fMRI activity for arbitrary words for which actual fMRI data is unavailable. A number of alternative approaches to determining these semantic features were described, including automatic derivation from the statistics of occurrence of a word in a very large text corpus, and the use of human judgments through crowd sourcing.
The talk concluded with a description of experiments to determine how these neural encodings unfold over time.
"Honest signals" are the subtle patterns of gesture, expressions and vocalizations that we use in our interactions with other people. They provide trustworthy cues to our attitudes towards those people and help to coordinate the combined activities of groups. An example is mimicry, the involuntary copying of one person's language, gesture and expressions by another during a conversation, which provides indicators of the success of the interaction as well as factors such as dominance. Alex Pentland, from the Human Dynamics Group at the MIT Media Laboratory, argues that as a communication mechanism language is a relative newcomer, layered on top of these more ancient signalling systems. In his talk he described his group's work on measuring these signals, primarily from audio streams, from data captured using 'sociometric badges' that record audio and coarse-grain body motion. The badges can capture data from up to several hundred people over extended periods of time. He gave examples, ranging from business plan presentations to speed dating encounters, where the outcome can be predicted accurately using social signals. Indeed, he estimated that in such situations approximately 40% of the variation in outcome is attributable to this type of signalling. Alex went on to describe experiments to investigate the relationship between 'modern' language and social signals, in which the social and task roles of individuals were inferred from audio and visual data. He showed that the roles defined by explicit semantic content closely match those defined by social signalling. He concluded by presenting the results of experiments that show that signalling behavior alone is a reliable predictor of group performance.
All three of these talks were exciting and were beautifully presented. Those of us in the audience whose interest is speech and language technology, were taken on a visit to the borders with cognitive science and shown phenomena that are clearly relevant to our goals. I was left with the conviction that effective spoken human-machine interaction will need to take account of these and many other similar ideas. The challenge, of course, is how.
On my final day in Florence I made another early start, this time to catch the presentations by Botticcelli et al at the Ufficci Gallery - unfinished business from my previous visit. Then a walk to the Piazzale Michelangelo for the fantastic view of the city.
Thanks to Julia Hirshberg, Tom Mitchell and Alex Pentland for providing copies of their slides and references to relevant material.
For more information, see:
Martin Russell is a Professor in the School of Electronic, Electrical and Computer Engineering at the University of Birmingham, Birmingham, UK. Email: m.j.russell@bham.ac.uk.
SLTC Newsletter, October 2011
Welcome to the next installment of the SLTC Newsletter of 2011. Well, the submission window for ICASSP-2012 is now closed and we are getting ready to start the review process for roughly 600 papers which were submitted in the speech and language processing areas, which continue to be the largest paper concentration at our yearly ICASSP meetings. Conference logistics are well on their way, so please visit the website IEEE ICASSP-2012. I also want to let everyone know that an overview article entitled "Trends in Speech and Language Processing" (J. Feng, B. Ramabhadran, J.H.L. Hansen, J.D. Williams) will be appearing in the January 2012 issue of the IEEE Signal Processing Magazine. This article is a result of the overview sessions which IEEE Signal Processing Society organized for ICASSP-2011, and is linked to the slides and video presentation from our session in speech and language processing. Many thanks to the co-authors for their work in bringing together +700 papers in the one hour overview session and three pages! I encourage you to read and share this article.
In the last newsletter, I talked about Grand Challenges in Speech & Language Processing, and highlighted several domains which are emerging in the field. In this issue, I would like to comment on a related aspect stemming from this initial discussion. The field of automatic speech recognition has been very active for more than thirty years, and continues to be a core research area for our community. However, in recent years, both at IEEE ICASSP as well as Interspeech conferences, the areas of speaker and language recognition have emerged as major areas of activity. Specifically, the number of papers and sessions in speaker recognition has grown significantly and now is one of the most active areas in the SLTC. One might ask what has prompted this increase? Well, much credit should go to the organizers of the biennial NIST SRE (Speaker Recognition Evaluation) [1] and NIST LRE (Language Recognition Evaluation) [2] competitions. While extensive research support has existed for the field of speech recognition, dialog and language technology over the past two decades, the level of research support for speaker ID (SID) and language ID (LID) has been quite modest. Organizers in the field recognized this, and formulated a biennial evaluation which has grown in stature and participation. In 2010, more than fifty teams worldwide participated in the NIST SRE-10. Many of these participations consisted of joint collaborations between universities, research laboratories, and industry. This blending of talent has resulted in major advances in the speaker recognition field to improve performance and address microphone and handset/channel mismatch including JFA (joint factor analysis), NAP (nuisance attribute projection), iVector, and others. This past summer, the NIST LRE-2011 was held, with 24 languages under consideration (as summarized in Table 1, taken from the NIST LRE 2011 write-up [3]).
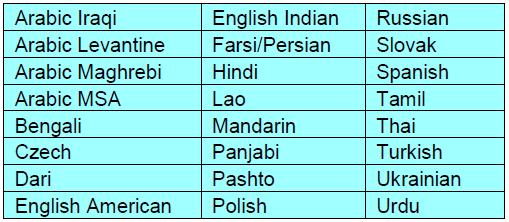
Table 1 – taken from "The 2011 NIST Language Recognition Evaluation Plan (LRE11)" [3]
While I noted that one of the grand challenges in our field can/should be “Speech Recognition for All Languages”, at some level one needs to recognize the language/dialect first before formulating or engaging an appropriate speech recognition solution. The advancements made in the NIST LRE have helped bring forth resources for many research laboratories in language ID, but a side effect is that these language resources help bring much needed speech and language materials to help expand the research activities in under-represented languages. There is a real cost in collecting, organizing, and running the NIST LRE (as well as NIST SRE), and the organizers and sponsors should be commended for their contributions to the speech and language communities.
I hope you might consider visiting several of the speaker ID (SID) and language ID (LID) sessions at the next ICASSP to be held in Kyoto, Japan in March 25-30, 2012. Until then, the SLTC will complete the review process of the submitted papers, and work to organize the sessions for this next meeting. I look forward to seeing everyone at ICASSP-2012. Best wishes…
John H.L. Hansen
October 2011
[1] NIST SRE: http://www.itl.nist.gov/iad/mig/tests/sre/2010/index.html
[2] NIST LRE: http://www.nist.gov/itl/iad/mig/lre.cfm
[3] http://www.nist.gov/itl/iad/mig/upload/LRE11_EvalPlan_releasev1.pdf
John H.L. Hansen is Chair, Speech and Language Processing Technical Committee.
SLTC Newsletter, October 2011
Since the Japanese Parliament (Diet) was founded in 1890, verbatim records had been made by manual shorthand over a hundred years. However, early in this century, the government terminated recruiting stenographers, and investigated alternative methods (Similar changes have taken place in many countries over last decades). The House of Representatives has chosen ASR for the new system [1]. The system was deployed and tested in 2010, and it has been in official operation from April 2011. This is the first automatic transcription system deployed in national Parliaments, except that online TV captioning has been done for the Czech Parliament [2].
The new system handles all plenary sessions and committee meetings. Speech is captured by the stand microphones in meeting rooms. Separate channels are used for interpellators and ministers. The speaker-independent ASR system generates an initial draft, which is corrected by Parliamentary reporters. Roughly speaking, the system’s recognition error rate is around 10%, and disfluencies and colloquial expressions to be corrected also account for 10%. Thus, reporters still play an important role.
Requirements for the ASR system are as follows. The first is high accuracy; over 90% is preferred. This can be easily achieved in plenary sessions, but is difficult in committee meetings, which are interactive, spontaneous, and often heated. The second requirement is fast turn-around. In the House, reporters are assigned speech for transcription in 5-minute segments. ASR should be performed almost in real-time, so reporters can start working promptly even during the session. The third issue is compliance to the standard transcript guidelines of the House. This can be guaranteed by using only the past Parliamentary meeting records for building the lexicon and language model.
In order to achieve high performance, acoustic and language models must be customized to Parliamentary speech; that is, they need to be trained with a large amount of the matched data. Fortunately, there is a large amount of data of Parliamentary meetings. There is a huge archive of official meeting records in text, amounting to 15M words per year, which is comparable to newspapers. There is also a huge archive of meeting speech, which amounts to 1200 hours per year. However, official meeting records are different from actual utterances due to the editing process by reporters. There are several reasons for this: differences between spoken-style and written-style, disfluency phenomena such as fillers and repairs, redundancy such as discourse markers, and grammatical corrections. In our analysis, Japanese has more disfluency and redundancy, but less grammatical corrections, because the Japanese language has a relatively free grammatical structure.
From these reasons, we need to build a corpus of Parliamentary meetings, which consists of faithful transcripts of utterances including fillers, aligned with official records. We prepared this kind of corpus in the size of 200 hours in speech or 2.4M words in text. The corpus is vital for satisfactory performance, but very costly. Moreover, it needs to be updated; otherwise, the performance would degrade in time.
In order to exploit the huge archive of Parliamentary meetings in a more efficient manner, we have investigated a novel training scheme by focusing on the differences between the official meeting record and the faithful transcript [1][3]. Although there are differences by 13% in words, 93% of them are simple edits such as deletion of fillers and correction of a word. These can be computationally modeled by a scheme of statistical machine translation (SMT). With the statistical model of the difference, we can predict what is uttered from the official records. By applying the SMT model to a huge scale of the past Parliamentary meeting records (200M words in text over 10 years), a precise language model is generated. Moreover, by matching the audio data with the model predicted for every speaker turn, we can reconstruct what was actually uttered. This results in an effective lightly-supervised training of the acoustic model, by exploiting 500 hours of speech that are not faithfully transcribed. As a result, we could build precise models of spontaneous speech in Parliament, and this model will evolve in time, reflecting the change of Members of Parliament (MPs) and topics discussed.
These acoustic and language models, developed by Kyoto University, have been integrated into the recognition engine or decoder of NTT Corporation [4], which is based on the fast on-the-fly composition of WFST (Weighted Finite State Transducers).
Evaluations of the ASR system have been conducted since the system was deployed in the last year. The accuracy defined by the character correctness compared against the official record is 89.4% for 108 meetings done in 2010 and 2011. When limited to plenary sessions, it is over 95%. No meetings got accuracy of less than 85%. The processing speed is 0.5 in real-time factor, which means it takes about 2.5 minutes for a 5-minute segment. The system can also automatically annotate and remove fillers, but automation of other edits is still under ongoing research.
The post-editor used by reporters is vital for efficient correction of ASR errors and cleaning transcripts. Designed by reporters, it is a screen editor, which is similar to the word-processor interface. The editor provides easy reference to original speech and video, by time, by utterance, and by character. It can speed up and down the replay of speech. A side effect of the ASR-based system is all of text, speech, and video are aligned and hyperlinked by speakers and by utterance. It will allow for efficient search and retrieval of the multi-media archive.
For system maintenance, we continuously monitor the ASR accuracy, and update ASR models. Specifically, the lexicon and language model are updated once a year to incorporate new words and topics. Note that new words can be added by reporters at any time. The acoustic model will be updated after the change of the Cabinet or MPs, which usually takes place after the general election. Note that these updates can be semi-automated without manual transcription in our lightly-supervised training scheme. We expect the system will improve or evolve with more data accumulated.
Tatsuya Kawahara is a Professor in the Graduate School of Informatics at Kyoto University. His email is kawahara [at] i [dot] kyoto-u [dot] ac [dot] jp.
<!-- TITLE --><h2>Detecting Intoxication in Speech</h2>
<!-- BY-LINE --><h3>Matthew Marge</h3>
<!-- INSTITUTION. This is only used on the front page, so put it in a comment here --><!-- Carnegie Mellon University -->
<!-- DATE (month) --><p>SLTC Newsletter, October 2011</p>
<!-- ABSTRACT. This is used both in the article itself and also on the table of contents -->
<p>
Researchers at Columbia are investigating ways to automatically detect intoxication in speech. William Yang Wang, currently a PhD student at Carnegie Mellon that worked on this team while a Master's student, discussed the project and its goals with us.
</p>
<!-- EXAMPLE SECTION HEADING. Use h4. Section headings are optional - no need if your article is short. -->
<h4>Overview</h4>
<!-- BODY. Use <p>...</p> - this will ensure paragraphs are formatted correctly. -->
<p>
Imagine a world where <a href="http://en.wikipedia.org/wiki/Driving_under_the_influence" target="_blank">DUI's</a> (driving under the influence violations) never occurred. How can this happen? Traditionally devices like breathalyzers can detect intoxication, but these tools are expensive and impractical for "passive operation" in vehicles. One arguably more practical alternative is that the cars themselves listen to the driver, detect that the potential driver is intoxicated, and prevent the car from starting. Researchers at Columbia are investigating a crucial problem in this space - ways to automatically detect intoxication in speech.
</p>
<p>
In a recent presentation at the <a href="http://emotion-research.net/sigs/speech-sig/The%20INTERSPEECH%202011%20Speaker%20State%20Challenge.pdf" target="_blank">Intoxication Sub-Challenge at Interspeech</a>, the <a href="http://www.cs.columbia.edu/speech/" target="_blank">Columbia group</a> discussed their approach [1, 2]. Their key intuition was to treat the intoxication of a person's speech similarly to a person's accent, and apply existing automatic methods to accent detection. The system they built could detect differences in the phonetic structure of sober and intoxicated speech.
</p>
<p>
<a href="http://www.cs.cmu.edu/~yww/" target="_blank">William Yang Wang</a>, currently a PhD student at Carnegie Mellon that worked on this team while a Master's student, discussed the project and its goals with us.
</p>
<p>
<b>SLTC:
What kind of system did your group build?</b>
<br>
<b>Wang:</b>
At Columbia, we have studied speaker states that do not map directly to the classic or even derived emotions: charismatic speech, deceptive speech, depression, and levels of interest. In this work, we are interested in building a system that can automatically classify intoxicated speech from sober speech, given only a very short sample from the speaker. This is a crucial task from the point of views of public safety and social welfare. In the United States, there were 164,755 alcohol related fatalities in a past window of ten years (1999-2008). A system to detect a person's level of intoxication via minimally invasive means would not only be able to significantly aid in the enforcement of drunk driving laws, but also ultimately save lives. The system should be easily applicable to the domain of in-car intoxication detection, as well as automatic speech recognizers and spoken dialog systems.
</p>
<p>
<b>How does it work?</b>
<br>
The traditional approaches to speaker state detection include two steps: the extraction of low-level acoustic features (e.g. <a href="http://en.wikipedia.org/wiki/Mel-frequency_cepstral_coefficient" target="_blank">MFCC</a>), and n-way direct classification or regression using maximum margin classifiers. However, this might not always yield optimum results because the model is too simple, and might not be able to capture subtle phonetic differences between drunk and sober speakers. When I first heard of this shared task from my advisor <a href="http://www.cs.columbia.edu/~julia/" target="_blank">Julia Hirschberg</a>, I was thinking that maybe we could cast this problem as a problem that we are more familiar with: an accent identification problem, where we assume intoxicated speakers speak a slightly different accent of the same language than sober speakers. In fact, <a href="http://www.cs.columbia.edu/~fadi/" target="_blank">Fadi Biadsy</a> has just finished his PhD thesis on automatic dialect and accent identification at Columbia, so we thought it would be an interesting idea to run his system on this dataset.
</p>
<p>
<b>Which properties of speech did you study in your work? Which yielded the best results?</b>
<br>
We have investigated high level prosodic, phone duration, phonotactic, and phonetic cues to intoxicated speech. The first thing we looked at was the n-gram frequencies of prosodic events in an utterance, where we hypothesize energetic and depressed intoxicated speakers might use higher and lower rates of emphasis (pitch accents) than sober speakers. In addition to this, a greater rate of disfluencies or intonational phrase boundaries might occur in intoxicated speech. Unfortunately, due to data sparsity and other problems, the final results using the prosodic approach were not as good as what we had in previous emotional speech classification tasks. The second property we looked at was the changes of phone durations in intoxication state. In our study, a simple vector space model of phone durations has been shown to be very effective, and the result was even better than the acoustic baseline that used more than 4000 low-level acoustic features. We then study a phonotactic based language/accent identification technique for this task, where we believe intoxicated speakers might use certain phones or words more frequently than others. The experiment results showed that our hypothesis was correct. Finally, we have investigated a state-of-the-art accent identification technique where we hypothesize intoxicated speakers realize certain phones differently than sober speakers. We built adapted Gaussian Mixture Models - Universal Background Models (GMM-UBMs) for each phone type in the data, generated GMM supervectors and used an upper-bound KL-divergence based linear kernel SVM to compare the similarity between two utterances. Our final system that combines this method with the phonotactic method achieved the best result, and it was significantly better than the majority and official baseline of the sub-challenge.
</p>
<p>
<b>What kind of impact do you foresee this work having?</b>
<br>
The most important impact in this work is that we successfully cast the unknown problem of intoxication detection to the problem of language and accent identification, which we have known for years. In the field of language and accent identification, NIST organizes language recognition evaluation workshops every two years, and some of the best systems from the workshop have already reached 3-4% equal error rate in a 30-second close-set dialect/accent identification task. This is definitely encouraging news for the emotional speech community, because the state-of-the-art emotion and speaker state detection systems still have much lower accuracy and cannot be compared with mature speech techniques like speech recognition, speaker and language identification. We also believe that it is necessary to investigate more prosodic cues to the speaker state and emotion detection tasks.
</p>
<p>
<b>Can you tell us a bit about the Intoxication Sub-Challenge at Interspeech this year? What were the goals of the challenge? What were your personal impressions of the sub-challenge?</b>
<br>
Definitely. Interspeech has organized three shared tasks on emotion, paralinguistic, and speaker state detection in the past three years respectively. All of them were very interesting tasks. This year, the organizers thought they would like to focus on a rarely studied speaker state: intoxication, and the goal was to identify interesting features that could characterize intoxication and approaches that can separate intoxicated speech efficiently. Personally speaking, I thought the organizers did a relatively good job in organizing the event, and it was a great idea to work on a shared dataset with researchers around the world. The challenge results are not the most important thing, but this kind of competition can definitely put our field forward. In terms of the suggestions, we might consider the following two questions in the future challenges: (1) what are the most appropriate evaluation metrics? (2) how could we preserve the authenticity of the data when creating training, development and test sets for the challenge?
</p>
<p>
We look forward to hearing more about intoxication detection in speech in future challenges!
</p>
<!-- BIBLIOGRAPHY -->
<h4>References</h4>
<ul>
<li>[1] Bjorn Schuller, Stefan Steidl, Anton Batliner, Florian Schiel, Jarek Krajewski. "<a href="http://emotion-research.net/sigs/speech-sig/The%20INTERSPEECH%202011%20Speaker%20State%20Challenge.pdf/" target="_blank">The INTERSPEECH 2011 Speaker State Challenge</a>", in Proceedings of the 12th Annual Conference of the International Speech Communication Association (INTERSPEECH 2011), Florence, Italy 28-31 Aug., 2011.</li>
<li>[2] Fadi Biadsy, William Yang Wang, Andrew Rosenberg, Julia Hirschberg, "<a href="http://www.cs.cmu.edu/~yww/papers/is2011submitted.pdf" target="_blank">Intoxication Detection using Phonetic, Phonotactic and Prosodic Cues</a>", in Proceedings of the 12th Annual Conference of the International Speech Communication Association (INTERSPEECH 2011), Florence, Italy 28-31 Aug., 2011.</li>
</ul>
<p>If you have comments, corrections, or additions to this article, please contact the author: Matthew Marge, <a href="http://mailhide.recaptcha.net/d?k=016R5yGSi4qZV42JdwdGKAQg==&c=yjBL7Ici6LRqdyHmjXs2KNeHbQt2FJLR5pTQ2lsi-Jo=" onclick="window.open('http://mailhide.recaptcha.net/d?k=016R5yGSi4qZV42JdwdGKAQg==&c=yjBL7Ici6LRqdyHmjXs2KNeHbQt2FJLR5pTQ2lsi-Jo=', '', 'toolbar=0,scrollbars=0,location=0,statusbar=0,menubar=0,resizable=0,width=500,height=300'); return false;" title="Reveal this e-mail address">mrma...@cs.cmu.edu</a>.</p>
<!-- OPTIONAL: INFORMATION ABOUT THE AUTHOR(S). OK TO INCLUDE LITTLE BIO, CONTACT INFO, RECENT WORK, RECENT PUBLICATIONS, ETC. USE <p><i> ... </i></p> -->
<p><i>Matthew Marge is a doctoral student in the Language Technologies Institute at Carnegie Mellon University. His interests are spoken dialog systems, human-robot interaction, and crowdsourcing for natural language research. </i></p>
<i><p>Editor's note: For more information, readers are referred to the papers presented at the 2011 Interspeech Speaker State Challenge: <a href="http://www.interspeech2011.org/conference/programme/Wednesday/Wed-Ses1-S1.html">Session 1</a> and <a href="http://www.interspeech2011.org/conference/programme/Wednesday/Wed-Ses2-S1.html">Session 2</a>. The challenge is documented in more detail <a href="http://emotion-research.net/sigs/speech-sig/is11-speaker-state-challenge">here</a>. For the intoxication challenge, it is interesting to note the wide variety of approaches of taken. For example, the winner of the Intoxication sub-challenge prize -- Bone et al, Intoxicated Speech Detection by Fusion of Speaker Normalized Hierarchical Features and GMM Supervectors -- relied on hierarchical organization of speech signal features, the use of novel speaker normalization techniques as well as the fusion of multiple classifier subsystems. The adopted features included spectral cues long used for speech recognition, and signal features of prosody, rhythm, intonation and pitch, and also voice quality cues such as hoarseness, creakiness, breathiness, nasality, and quiver, all inspired by phonetics research and speech analysis results in the published literature. -- Jason Williams, 2010-10-28.</p></i>
SLTC Newsletter, October 2011
The latest in the SemDial series of workshops in the semantics and pragmatics of dialogue was recently held in Los Angeles on September 21-23.
Researchers presented research from linguistic, psychological, and artificial intelligence approaches to language; it was the first in the SemDial series of workshops to be presented outside of Europe.
As an example of the research presented: Robin Cooper and Jonathan Ginzburg discussed negation in dialogue, Evgeny Chukharev-Hudilainen presented results of a study on the use of keystroke logging for structuring discourse in text-based computer-mediated dialogues, and Nigel Ward introduced an approach to identifying and visualizing co-occurent words given temporal offsets.
Hannes Rieser discussed a corpus study which analyzed a number of gesture types to determine their function within a route-description dialogue; gesture types included those for acknowledgments, turn allocation, interruption, and continuations, and the gestures were described from the perspective of the PTT dialogue model. Martin Johansson, Gabriel Skantze, and Joakim Gustafson described a data-collection approach used to acquire direction dialogues for a robotic navigation task.
Sophia Malamud and Tamina Stephenson proposed a "conversational scoreboard" model that leverages the levels of force of various types of declarative utterances. Richard Kunert, Raquel Fernandez, and Willem Zuidema describe a corpus study quantifying the complexity of speech in child-mother dialogues. Daria Bahtina described alignment in dialogues in which speakers are using different (though intelligible) languages, using Estonian-Russian dialogues.
Invited speakers included Lenhart Schubert discussing Natural Logic and inference, Jerry Hobbs discussing emergent structure in multiparty decision-making dialogues, Patrick Healey providing evidence against uniformly close co-ordination of dialogue structures, and David Schlangen on incremental processing. Poster sessions and social events were also part of the workshop.
For more information, see the web page of SemDial 2011 which includes the program and proceedings.
SLTC Newsletter, October 2011
The latest in the SemDial series of workshops in the semantics and pragmatics of dialogue was recently held in Los Angeles on September 21-23.
Researchers presented research from linguistic, psychological, and artificial intelligence approaches to language; it was the first in the SemDial series of workshops to be presented outside of Europe.
As an example of the research presented: Robin Cooper and Jonathan Ginzburg discussed negation in dialogue, Evgeny Chukharev-Hudilainen presented results of a study on the use of keystroke logging for structuring discourse in text-based computer-mediated dialogues, and Nigel Ward introduced an approach to identifying and visualizing co-occurent words given temporal offsets.
Hannes Rieser discussed a corpus study which analyzed a number of gesture types to determine their function within a route-description dialogue; gesture types included those for acknowledgments, turn allocation, interruption, and continuations, and the gestures were described from the perspective of the PTT dialogue model. Martin Johansson, Gabriel Skantze, and Joakim Gustafson described a data-collection approach used to acquire direction dialogues for a robotic navigation task.
Sophia Malamud and Tamina Stephenson proposed a "conversational scoreboard" model that leverages the levels of force of various types of declarative utterances. Richard Kunert, Raquel Fernandez, and Willem Zuidema describe a corpus study quantifying the complexity of speech in child-mother dialogues. Daria Bahtina described alignment in dialogues in which speakers are using different (though intelligible) languages, using Estonian-Russian dialogues.
Invited speakers included Lenhart Schubert discussing Natural Logic and inference, Jerry Hobbs discussing emergent structure in multiparty decision-making dialogues, Patrick Healey providing evidence against uniformly close co-ordination of dialogue structures, and David Schlangen on incremental processing. Poster sessions and social events were also part of the workshop.
For more information, see the web page of SemDial 2011 which includes the program and proceedings.
SLTC Newsletter, October 2011
Interspeech 2011 was held in Florence, Itally, on 27-31 August. The first three days of the conference began with excellent invited plenary talks by Julia Hirschberg, Tom Mitchell and Alex Pentland. As is the norm for these talks, there is not necessarily a printed version in the proceedings. This article presents a summary of those talks and links to relevant publications by the presenters.
My only previous visit to Florence was in 1975. I was a first year undergraduate student on an 'Inter-rail' tour of Europe. I had never been outside the UK, and Florence was the most exotic place that I had ever visited. I looked forward to my return visit for Interspeech 2011 with keen anticipation. I was not disappointed with the conference or the city. In particular the invited plenary talks at the start of each day were fascinating. Each of these talks addressed a different aspect of the interface between speech and language technology and cognitive science. The first, by Julia Hirschberg from Columbia University, examined the phenomenon of entrainment, whereby the communicative styles of individuals engaged in conversation tend to converge, the next talk, by Tom Mitchell from Carnegie Mellon University, described research into the neural representation of words, while the final talk, by Alex Pentland from the MIT Media Laboratory, concerned "honest signals", the subtle patterns of gesture, expression and speech that underpin our interactions with others. This short article presents a summary of the plenary sessions, with links and references to some relevant support information.
Julia Hischberg, Tom Mitchell and Alex "Sandy" Pentland deliver their invited plenary talks and Interspeech 2011, Florence, Italy 27-31 August 2011.
'Entrainment', or adaptation, accommodation, alignment, priming or the 'chameleon effect', refers to the way that, in natural conversational speech, people tend to adapt their communicative behavior to that of their conversational partner. From the perspective of speech technology, this presents both problems and opportunities. For example, in speaker verification entrainment might cause the speech of two individuals to become more difficult to distinguish as their conversation progresses, whereas in a spoken dialogue system the same phenomenon might be exploited to modify different dimensions of a user's speech to improve performance, or to adapt the automatic system to make it more acceptable to the user. Julia presented evidence from published studies of entrainment in many different aspects of spoken language. She then went on to describe her own work and that of her collaborators at Columbia University, investigating evidence of different types of entrainment using the 'Columbia Games Corpus'. She described lexical entrainment, the tendency of individuals to collaborate on their choice of what to call something, how participants in the game converge in terms of their usage of high frequency words and affirmative cue words (different ways of saying "yes"), and how this convergence correlates with task success and dialogue coordination. She then turned from entrainment over entire conversations to evidence of 'local' entrainment in the neighborhood of 'backchannels' - the short utterances that we use to indicate that we are paying attention.
This was a fascinating talk, exposing an aspect of human communication that we are only just beginning to contemplate from the perspective of technology. There are also interesting connections with Alex Pentland's plenary talk, which is described below.
I was astonished by the progress that has been made in this area. Tom described the work conducted by his neurosemantics research team at Carnegie Mellon University on the relationship between word stimuli (in the form of words or images) and the resulting patterns of brain activation in an individual, measured by functional MRI (fMRI). He showed that standard pattern classification techniques can be trained to identify the word corresponding to one of these stimuli from the fMRI pattern. Moreover, he showed that these patterns are sufficiently similar across people that a classifier trained on images from one population can classify the fMRI images of a new subject (including, from the evidence of a video that we were shown, those of a well-known US TV presenter!).
In the next part of his talk Tom described how machine learning techniques can be used to predict patterns of brain activity associated with the meaning of words, transforming machine learning into a tool for studying the brain. This is achieved by representing a word as a vector of latent 'semantic features' and then learning the relationships between these sets of features and the corresponding patterns of brain activity. Thus it becomes possible to predict fMRI activity for arbitrary words for which actual fMRI data is unavailable. A number of alternative approaches to determining these semantic features were described, including automatic derivation from the statistics of occurrence of a word in a very large text corpus, and the use of human judgments through crowd sourcing.
The talk concluded with a description of experiments to determine how these neural encodings unfold over time.
"Honest signals" are the subtle patterns of gesture, expressions and vocalizations that we use in our interactions with other people. They provide trustworthy cues to our attitudes towards those people and help to coordinate the combined activities of groups. An example is mimicry, the involuntary copying of one person's language, gesture and expressions by another during a conversation, which provides indicators of the success of the interaction as well as factors such as dominance. Alex Pentland, from the Human Dynamics Group at the MIT Media Laboratory, argues that as a communication mechanism language is a relative newcomer, layered on top of these more ancient signalling systems. In his talk he described his group's work on measuring these signals, primarily from audio streams, from data captured using 'sociometric badges' that record audio and coarse-grain body motion. The badges can capture data from up to several hundred people over extended periods of time. He gave examples, ranging from business plan presentations to speed dating encounters, where the outcome can be predicted accurately using social signals. Indeed, he estimated that in such situations approximately 40% of the variation in outcome is attributable to this type of signalling. Alex went on to describe experiments to investigate the relationship between 'modern' language and social signals, in which the social and task roles of individuals were inferred from audio and visual data. He showed that the roles defined by explicit semantic content closely match those defined by social signalling. He concluded by presenting the results of experiments that show that signalling behavior alone is a reliable predictor of group performance.
All three of these talks were exciting and were beautifully presented. Those of us in the audience whose interest is speech and language technology, were taken on a visit to the borders with cognitive science and shown phenomena that are clearly relevant to our goals. I was left with the conviction that effective spoken human-machine interaction will need to take account of these and many other similar ideas. The challenge, of course, is how.
On my final day in Florence I made another early start, this time to catch the presentations by Botticcelli et al at the Ufficci Gallery - unfinished business from my previous visit. Then a walk to the Piazzale Michelangelo for the fantastic view of the city.
Thanks to Julia Hirshberg, Tom Mitchell and Alex Pentland for providing copies of their slides and references to relevant material.
For more information, see:
Martin Russell is a Professor in the School of Electronic, Electrical and Computer Engineering at the University of Birmingham, Birmingham, UK. Email: m.j.russell@bham.ac.uk.
SLTC Newsletter, October 2011
Over the past few years, IBM Research has been actively involved a project known as Translingual Automatic Language Exploitation System (TALES). The objective of the TALES project is to translate news broadcasts and websites from foreign languages into English. TALES is built on top of the IBM Unstructured Information Management Architecture (UIMA) platform. In this article, we provide an overview of the TALES project and highlight in more detail some of the new research directions.
TALES allows foreign-language news broadcasts and websites to be accessed and indexed by English speakers. An example of the TALES system is shown in Figure 1. In the past, this project has focused in four main research areas [1].
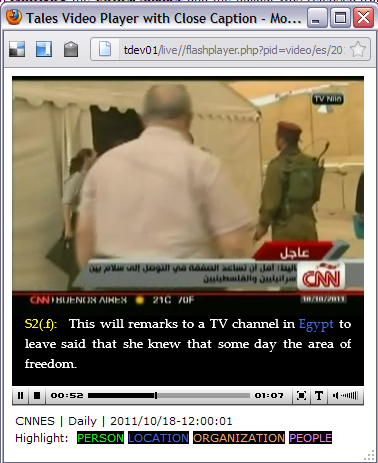
Figure 1: Example of TALES system translating a Foreign Broadcast into English.
Speech-to-text is the problem of recognizing spoken words (for example from broadcast news dialogues) and converting this into appropriate text, in essence this is the main problem in automatic speech recognition (ASR). Challenges in this area included recognizing speech in noisy environments and processing speech with different accents. Better speaker and dialect detection engines helped to address these issues.
Named entities are spans of text corresponding to real-life entities, including persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. Special care of named-entities is vital for a good translation system. The TALES project looked at handling a wide variety of incoming texts, for example speech recognition output which is upper-case and has no punctuation.
Machine translation (MT) is the problem of translating text from one language to another, for example from French to English. The MT model was developed over many years, and IBM itself pioneered statistical machine translation in the early 90s. Initial challenges in the MT area included dealing with words not found in standard dictionaries, as well as proper translations of named entities. To address these issues, an MT model was developed that received daily updates based on user feedback of phrases which could not be translated correctly, for example out-of-vocabulary words.
At the heart of any end-user system is the necessity to properly display appropriate information to the user. The TALES project displays translated transcriptions as subtitles/closed-captioning, together with the video, looking at intelligent segmentation and timing algorithms for effective display. In addition, a Web translation tool allows for translations to be available as soon as they are available, rather than waiting for an entire page to be translated.
Much of this research has led to a successfully deployed TALES system which lets users search search foreign-language news, play back streaming video with English closed captioning, monitor live video with low latency time, browse and translate foreign websites, etc. Currently, TALES supports Arabic, Chinese, Spanish and English.
One current research direction in the TALES project, inspired and sponsored by the DARPA GALE program, has focused on information extraction. Specifically, this allows users to search for information on people in broadcasts/websites, such as biographical information, where a person has been, acquaintances of the person, etc. This information is organized into various templates, and given a structured query by the user, the TALES system returns relevant information in an organized, detailed fashion.
An algorithm developed at IBM [2] which makes use of both statistical and rule-based systems, is used to return back relevant information to a structured query. [2] explores the problem of identifying a collection of relevant sentences (i.e. snippets) in response to a structured query. Rule-based systems are a popular approach to the snippet selection problem, as they are easy to implement and have good performance on small, structured tasks. However, if the data is noisy or large, rule-based systems are limited in performance. Alternatively, statistical-based approaches are much more generalizable for larger, noisier data sets, though require a significant amount of data to train a system.
[2] explores combining the benefits of both rule-based and statistical-based systems. Specifically, a rule-based system is used to bootstrap the annotation of training data for a statistical system. The motivation for this is twofold. First, a rule-based system allows a working prototype to quickly be designed that can guide the development of a statistical-system. Second, a rule-based system can be used to filter large amount of training data into a relevant subset that can be used by the statistical system. The proposed approach is compared against both statistical and rule-based systems alone on a snippet selection task, and was found to produce a better set of relevant queries compared to the rule/statistical-based approaches alone.
The TALES system was a result of contributions by many researchers at IBM, including Salim Roukos, Radu Florian, Todd Ward, Leiming Qian and Jerry Quinn. Also, thank you to Radu Florian and Sasha Caskey of IBM Research for useful discussions related to the content of this article.
[1] http://domino.watson.ibm.com/comm/research.nsf/pages/r.nlp.innovation.tales.html
[2] D.M. Bikel at al., "Snippets: Using Heuristics to Bootstrap a Machine Learning Approach", in Handbook of Natural Language Processing and Machine Translation: DARPA Global Autonomous Language Exploitation, 2011.
If you have comments, corrections, or additions to this article, please contact the author: Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling. Email: tsainath@us.ibm.com
SLTC Newsletter, October 2011
Editor's note: The AVIOS Speech Application Student Contest was first covered in a newsletter article in 2009. Over the past 2 years ago, the contest has continued. The article below is an update to the original article, covering the full 5-year history of the contest.
AVIOS, the Applied Voice Input/Output Society, is a non-profit foundation dedicated to informing and educating developers of speech applications on best practices for application construction and deployment. In early 2006 we decided to focus this goal on students by giving them an opportunity to demonstrate their developmental competence to the speech community. The competition has now grown into an annual contest whose winners are substantially remunerated for their efforts, and whose winning applications are posted on our website.
The development of a speech application contest requires multiple distinct activities:
Ideally, an application development platform suitable for student use must be cost-free to the student, and approachable without an extensive learning curve. Students should be able to focus on intricacies of speech / multi-modal application development without having to master complex multi-layered development environments. After all, contest entries are typically developed from concept through delivery in a single college semester. VoiceXML platforms such as BeVocal, Nuance Café, Angel, CueMe and Voxeo Prophecy, as well as multi-modal platforms such as the Opera Multimodal Browser have proven well suited to meet these requirements. In addition, students with prior Microsoft development experience have successfully developed applications using SAPI and .NET, and even WinMobile5.
Each year we have attempted to extend the palette of available platforms to encourage student exploration. We've recommend sophisticated development environments such as Voxeo's VoiceObjects platform and CMU's RavenClaw/Olympus, and are encouraging the use of AT&T's Speech MashUp. In the future we hope to negotiate no-cost access to a number of other full-featured speech application generation environments.
Recruiting sponsors for the contest is fundamental to the success of the program. Sponsors provide not only prizes for winners, but endorsement of their favorite development platform. Endorsement includes 'getting started' instruction, reference documentation, and access to technical support for students who have chosen to use that platform. Sponsoring institutions receive recognition on our website and at our annual conference, and are offered access to student resumes.
Marketing the contest throughout the speech community, especially to individuals and organizations who are focused on teaching speech technology, is vital to the success of the program. We reach out to both the academic and commercial communities to explicitly notify anyone engaged with students to ensure they receive documentation needed to stimulate student participation.
In order to ensure valid and unbiased selection of winners, we have selected several a priori criteria for evaluating speech / multimodal application quality. Criteria include robustness, usefulness, technical superiority, user friendliness, and innovation; and in an effort to ensure objectivity through quantification, each criterion is summarized using a 5-point Likert scale.
Contest applications have been evaluated by speech technology leaders from companies including Microsoft, Nuance, Convergys, Google, SpeechCycle, and Fonix on the basis of technical superiority, innovation, user-friendliness, and usefulness of each application. Judges typically have a decade or more of experience in the speech technology field and explicit experience in the design, development, deployment, and utilization of speech and multi-modal applications. Each judge possessed sufficient computer resource to access student entries their intended deployment channel (e.g., a judge must have access to the delivery platform, a PC, tablet, or smartphone, if (s)he is to judge a student project built for that device). Judges independently evaluate each student project, then the evaluation scores and associated written evaluations are consolidated and ranked. Judges then meet physically or virtually to review the rankings, possibly adjusting ranks to match shared observations, and finally selecting the winners and runners-up.
In the past five years, students from more than 10 academic institutions in 4 countries have participated in the contest. Winning applications included the following:
The contest fostered creative thinking in the use of speech technology and in the development of speech and multimodal applications. For the past five years, the contest has exposed students to a variety of speech technologies, including:
The above corporate sponsors have provided prizes such as software packages, popular hardware and monetary awards, including airfare and lodging for attending Voice Search Conference, to contest winners. In addition to experiences with commercial products, students were also able to use university prototypes, including CMU's RavenClaw/Olympus and MIT's WAMI.
An unanticipated benefit of the contest is to help students learn more about the corporate environment and to help the corporate sponsors identify emerging talent. Comments from participating students indicate that the contest has been a success: "The contest was a great chance for me to gain some in-depth knowledge." "I was very satisfied with learning to write voice applications." "There is a notable difference between theory and practice in speech recognition", and from one sponsor, "Wow! I want to contact that student!"
For more information about past contest entries and winners, the current contest, and future contests, please see the AVIOS web site at www.avios.com.
K. W. "Bill" Scholz is President of NewSpeech, LLC and President of AVIOS
Deborah Dahl is Principal of Conversational Technologies and Chair of the AVIOS Student Application Contest
SLTC Newsletter, October 2011
IVA 2011 is a research conference on Intelligent Virtual Agents. Intelligent Virtual Agents (IVAs) are animated embodied characters with interactive human-like capabilities such as speech, gestures, facial expressions, head and eye movement. Virtual agents have capabilities both to perceive and to exhibit human-like behaviours. Virtual characters enhance user interaction with a dialogue system by adding a visual modality and creating a persona for a dialogue system. They are used in interactive systems as tutors, museum guides, advisers, signers of sign language, and virtual improvisational artists.
Intelligent Virtual Agents conference is an annual event started in 1999. The conference brings together researchers from diverse fields of artificial intelligence, psychology, computer science, speech, and linguistics. This year the conference gathered over 100 participants and featured presentations sessions on the following topics:
In an invited talk, Dr. Jens Edlund described motivation and approaches for "creating systems that cause a user to communicate in the same way as with a human". This theme was reflected in many of the presentations throughout the conference that described research on various behavioural aspects of virtual agents. In his talk, Jens contrasted the evolution of communication capabilities of interactive systems with human communication learning. Children learn non-verbal interaction such as prosody and gestures before they actually learn words. Communicative systems on the other hand "learned to speak" before they acquired the non-verbal behaviour capabilities. Research on dialogue started with a focus on verbal communication. Current research on virtual agents focuses on adding non-verbal behaviour capabilities to spoken systems. Presentations at IVA2011 included studies of virtual agents perceiving user's mood and personality, using prosody for more realistic and context dependent realization of speech, gesture, and establishing rapport with a user. These non-verbal capabilities complement verbal capabilities of interactive system bringing human-system communication one step closer to human-human communication.
Virtual agents are used increasingly in applications. Virtual agents presented at IVA2011 included museum guides Ada and Grace (D. Traum et al.). The characters answer visitors' questions and chat with each other to present visitors with museum information in an entertaining and engaging manner. Tinker (T. Bickmore et al.) was another museum guide volunteer presented at IVA. Tinker has been deployed at the Science Museum in Boston for over three years and has had over 125,000 users interact with it. Museum guide characters are designed to engage and interest users enticing them to communicate with the system longer and to learn from this communication. Installations in public places such as museums allow researchers access to a large pool of subjects while bringing technology to the end users and making an impact.
Other examples of applications include improvisational theatre agents (A. Brisson et al., B. Magerko et al.), agents listeners that provide natural non-verbal feedback to a speaker/story teller (Wang et al., I. De Kok and D. Heylen), and virtual interviewers (Astrid M. von der Pütten et al.).
IVA2011 featured demonstrations and presentations on an emerging standard for creating virtual humans, Behaviour Markup Language (BML) . BML is XML-based language for specifying behaviour of a virtual agent [1]. A BML realizer is software modules that steer behaviour of a virtual human. Several BML realizers (virtual agents) have been recently developed and made publicly available:
These realizers can be integrated with an existing dialogue system or used for creating animations of communication between virtual agents. Connecting a virtual agent to an existing application involves sending BML to the Virtual Human and receiving feedback about its performance (see links for integration instructions).
As speech is one of the most important capabilities of a virtual agent, research areas of IVA and speech are closely related. A fully functional virtual agent requires speech and natural language processing (NLP) capabilities in order to hold a conversation with a user. IVAs on the other hand, can be used for evaluating speech and NLP applications.
Evaluation of natural language applications is a challenging task which often requires human involvement. Recently researchers started using task-based evaluation of systems using virtual environments. For example, GIVE challenge was used in the past two years for evaluation of referring expression generation. In a challenge evaluation, system capabilities are evaluated based on a user performance and task completion. GIVE challenge is set up as a game and involves players following automatically generated instructions. Different natural language generation (NLG) algorithms create different instructions. System's performance is judged based on users' task completion, response time, and satisfaction with the system.
Introducing virtual agents into evaluation challenges could be the next step for evaluation of language systems and could be used for task-based evaluation of dialogue systems or its components. A dialogue system may be evaluated as a user interacts with an agent or observes interaction between virtual agents in a game-like environment. Introducing agents would create a more interesting evaluation scenarios for analysing different aspects of a dialogue system including NLG, dialogue management, and language understanding.
Proceedings of the IVA2011 conference are available on SpringerLink.
Thanks to Dennis Reidsma for providing links for BML description and BML realizers.
If you have comments, corrections, or additions to this article, please contact the author: Svetlana Stoyanchev, s.stoyanchev [at] gmail [dot] com
SLTC Newsletter, October 2011
This article discusses how cloudcomputing and crowdsourcing are changing the speech science world in both, academia and industry. How are these paradigms interrelated? How do different areas of speech processing make use of cloudcomputing and crowdsourcing? Which role do performance, pricing, security, ethics play?
Many, if not most, of the difficulties associated with the development of speech technology are related to shortage of resources. To give some examples:
Generally, one can distinguish between two areas of resources:
Up until now, elevator pitches, panel discussions at industry shows, or scientific articles could use any shortage in one of these areas as excuse for doing a halfhearted job. But these days are numbered with the rise of two technologies matching the above resource areas:
Returning to the above examples, how do cloudcomputing and crowdsourcing cope with these particular cases?
In conclusion, cloudcomputing and crowdsourcing are ideal techniques to enhance speech technology in many areas. There are, however, a number of caveats to this proposition:
[1] R. Kuhn and R. de Mori, "The Application of Semantic Classification Trees to Natural Language Understanding," IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 17, no. 5, 1995.
[2] J. Williams, "Incremental Partition Recombination for Efficient Tracking of Multiple Dialog States," in Proc. of the ICASSP, Dallas, USA, 2010.
[3] S. Buchholz and J. Latorre, "Crowdsourcing Preference Tests, and How to Detect Cheating," in Proc. of the Interspeech, Florence, Italy, 2011.
[4] M. Marge, "Interview: MTurk NAACL Workshop Organizers Talk Crowdsourcing, Speech, and the Future of Unsupervised Learning," in SLTC Newsletter, July 2010.
[5] F. Jurcicek, S. Keizer, M. Gasic, F. Mairesse, B. Thomson, K. Yu, and S. Young, "Real User Evaluation of Spoken Dialogue Systems Using Amazon Mechanical Turk," in Proc. of the Interspeech, Florence, Italy, 2011.
[6] S. Banerjee and M. Marge, "Speech Transcription using Amazon's Mechanical Turk Rivaling Traditional Transcription Methods," in SLTC Newsletter, July 2009.
[7] D. Suendermann, J. Liscombe, K. Evanini, K. Dayanidhi, and R. Pieraccini, "From Rule-Based to Statistical Grammars: Continuous Improvement of Large-Scale Spoken Dialog Systems," in Proc. of the ICASSP, Taipei, Taiwan, 2009.
[8] G. Parent and M. Eskenazi, "Speaking to the Crowd: Looking at Past Achievements in Using Crowdsourcing for Speech and Predicting Future Challenges," in Proc. of the Interspeech, Florence, Italy, 2011.
[9] P. Ipeirotis, F. Provost, and J. Wang, "Quality Management on Amazon Mechanical Turk," in Proc. of the HCOMP, Washington, USA, 2010.
David Suendermann is full professor of computer science at DHBW Stuttgart and the principal speech scientist of SpeechCycle, New York.
Email: david@speechcycle.com
WWW: suendermann.com