


Popular Pages
Today's:
- Submit a Manuscript
- Information for Authors
- (EUSIPCO 2025) 2025 European Signal Processing Conference
- IEEE Signal Processing Letters
- IEEE Transactions on Image Processing
- (MLSP 2024) 2024 IEEE International Workshop on Machine Learning for Signal Processing
- IEEE Transactions on Multimedia
- (SLT 2024) 2024 IEEE Spoken Language Technology Workshop
- IEEE/ACM Transactions on Audio Speech and Language Processing
- Conferences & Events
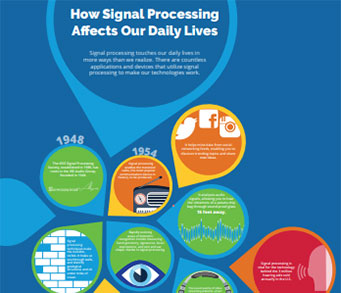
- Signal Processing 101
- Information for Authors-SPL
- SPS Webinar: Pol-InISAR Approach for 3D Imaging of Non-Cooperative Targets
- Guidelines
- IEEE Journal of Selected Topics in Signal Processing
All time:
- Information for Authors
- Submit a Manuscript
- IEEE Transactions on Image Processing
- 404 Page
- IEEE/ACM Transactions on Audio Speech and Language Processing
- IEEE Transactions on Information Forensics and Security
- IEEE Transactions on Multimedia
- IEEE Signal Processing Letters
- IEEE Transactions on Signal Processing
- Conferences & Events
- IEEE Journal of Selected Topics in Signal Processing
- Information for Authors-SPL
- Conference Call for Papers
- Signal Processing 101
- IEEE Signal Processing Magazine
Last viewed:
- Publications & Resources
- IEEE Signal Processing Letters
- About the Magazine
- Information for Authors
- SPS-DSI (DEGAS) Webinar: Edge Varying Graph Neural Networks and Their Stability
- Statistical Analysis for Speaker Recognition Evaluation With Data Dependence and Three Score Distributions
- (AVSS 2024) 2024 IEEE International Conference on Advanced Video and Signal-Based Surveillance
- IEEE/ACM Transactions on Audio Speech and Language Processing
- Call For Proposals: IEEE ICIP 2027
- Seizure Detection Challenge: ICASSP 2023
- IEEE Open Journal of Signal Processing
- SPS SLTC/AASP TC Webinar: End-to-End Automatic Speech Recognition
- (CoSeRa 2024) 2024 International Workshop on the Theory of Computational Sensing and its Applications to Radar, Multimodal Sensing and Imaging
- IEEE Transactions on Multimedia
- Signal Processing 101
TMM Volume 25 | 2023



Top Reasons to Join SPS Today!
1. IEEE Signal Processing Magazine
2. Signal Processing Digital Library*
3. Inside Signal Processing Newsletter
4. SPS Resource Center
5. Career advancement & recognition
6. Discounts on conferences and publications
7. Professional networking
8. Communities for students, young professionals, and women
9. Volunteer opportunities
10. Coming soon! PDH/CEU credits
Click here to learn more.

SPS on Twitter
- DEADLINE EXTENDED: The 2023 IEEE International Workshop on Machine Learning for Signal Processing is now accepting… https://t.co/NLH2u19a3y
- ONE MONTH OUT! We are celebrating the inaugural SPS Day on 2 June, honoring the date the Society was established in… https://t.co/V6Z3wKGK1O
- The new SPS Scholarship Program welcomes applications from students interested in pursuing signal processing educat… https://t.co/0aYPMDSWDj
- CALL FOR PAPERS: The IEEE Journal of Selected Topics in Signal Processing is now seeking submissions for a Special… https://t.co/NPCGrSjQbh
- Test your knowledge of signal processing history with our April trivia! Our 75th anniversary celebration continues:… https://t.co/4xal7voFER
IEEE SPS Educational Resources
IEEE SPS Resource Center

IEEE SPS YouTube Channel
